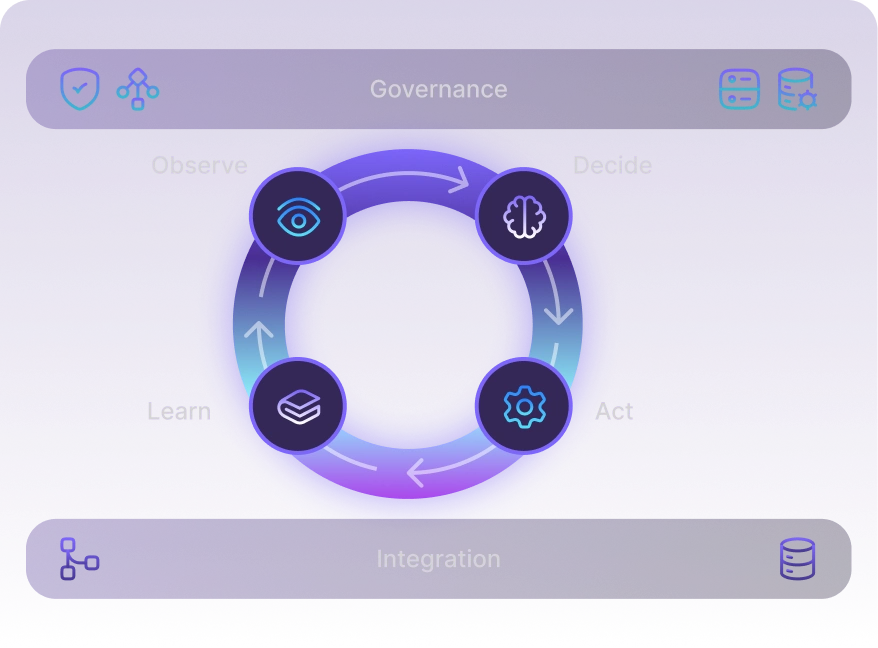
Intake
Read the incident + service context (CI, recent changes, similar cases)

Triage
Classify severity/owner, dedupe noise, link related incidents

Diagnose
Propose cause + recommended actions using runbooks/patterns

Approve
Apply risk policy (auto / human approval / block)

Execute & validate
Run approved steps and confirm outcome

Document & learn
Update the ticket, draft RCA notes, create follow-ups