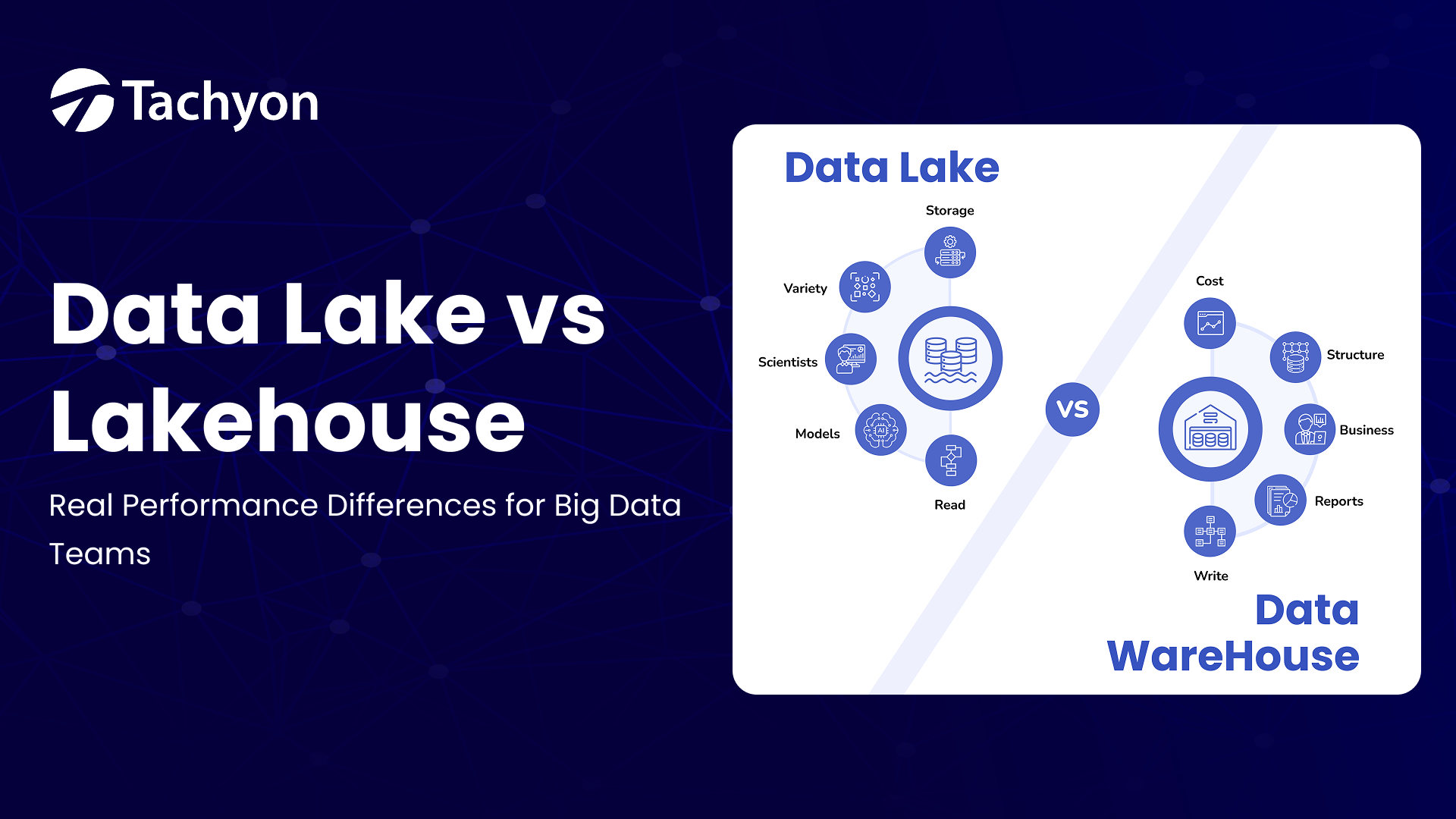
Most SAP enterprises are deciding whether to keep scaling a classic data lake or shift to a lakehouse. This post clarifies the real trade-offs—performance at scale, ACID reliability, streaming, governance, and cost—through the lens of SAP Datasphere/HANA and modern open table formats (Delta/Iceberg/Hudi). You’ll leave with a simple rubric for when a lake is enough, when a lakehouse pays off, and how to run them side-by-side without derailing your SAP roadmap.
Architecture Overview: Data Lake vs Lakehouse
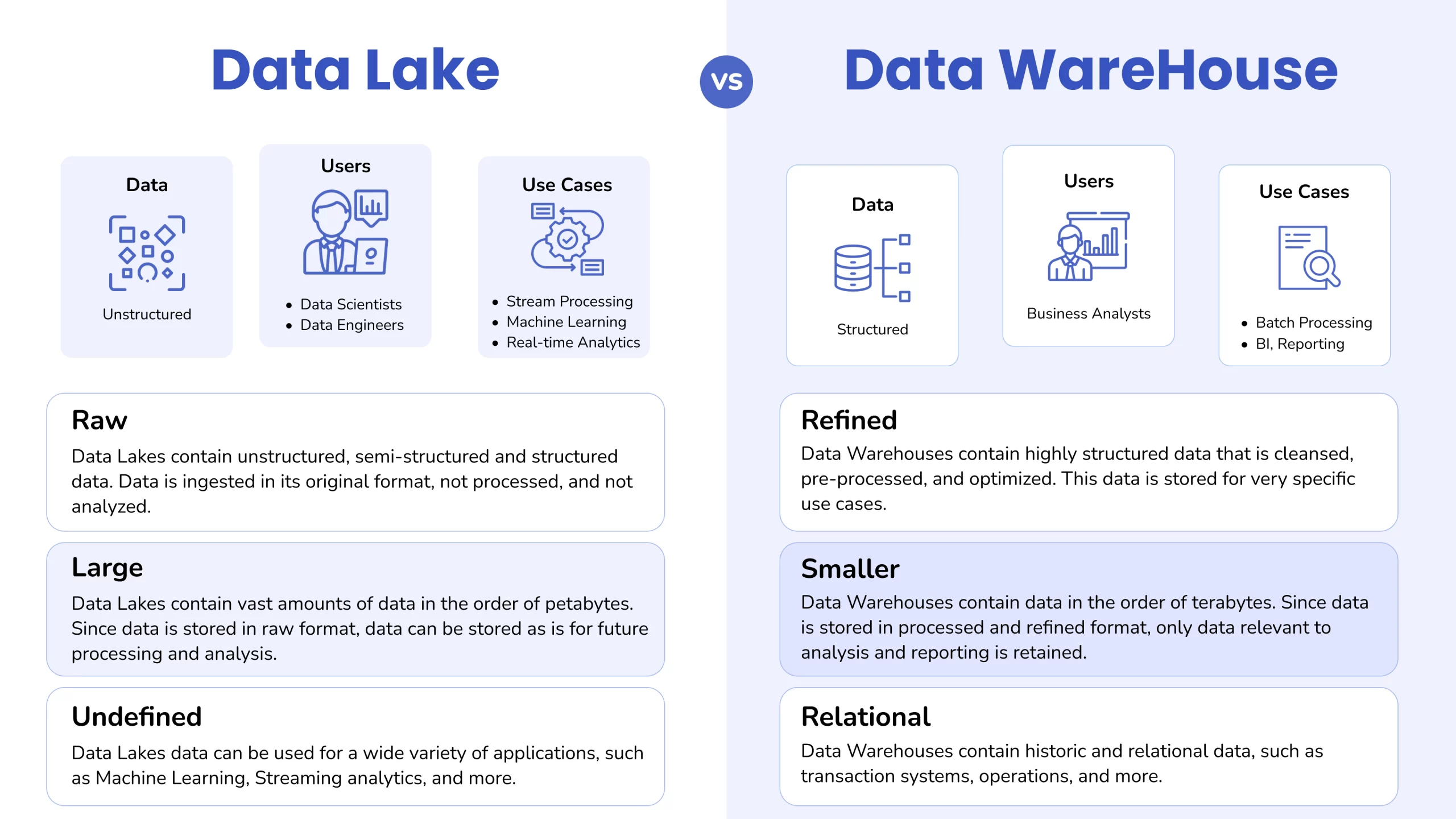
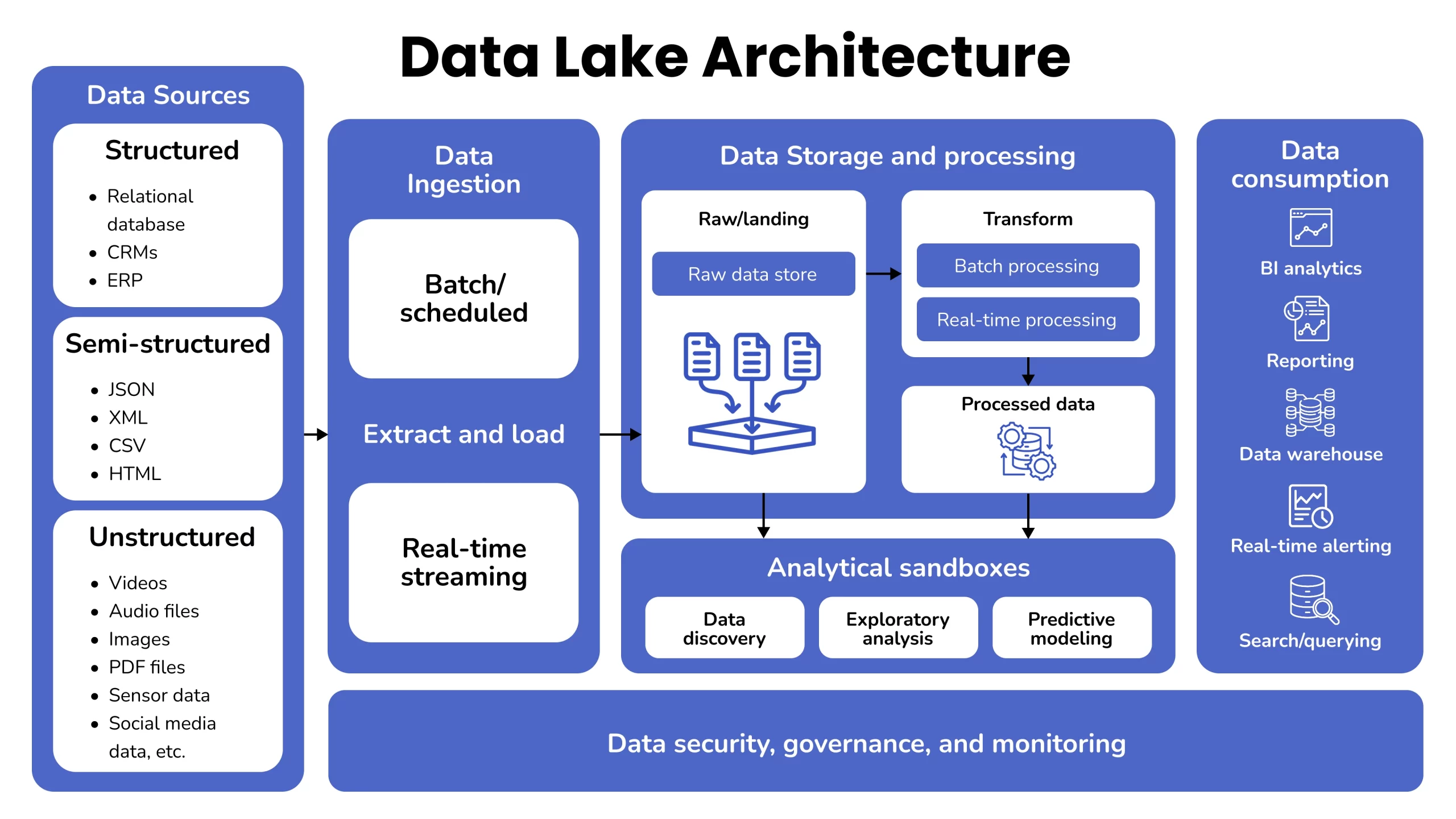
Data lakes and lakehouses have key differences in how they store, process, and manage data. Teams need to understand these differences to pick the right approach for their analytical needs.
Storage Design: Flat Object Store vs Layered Metadata
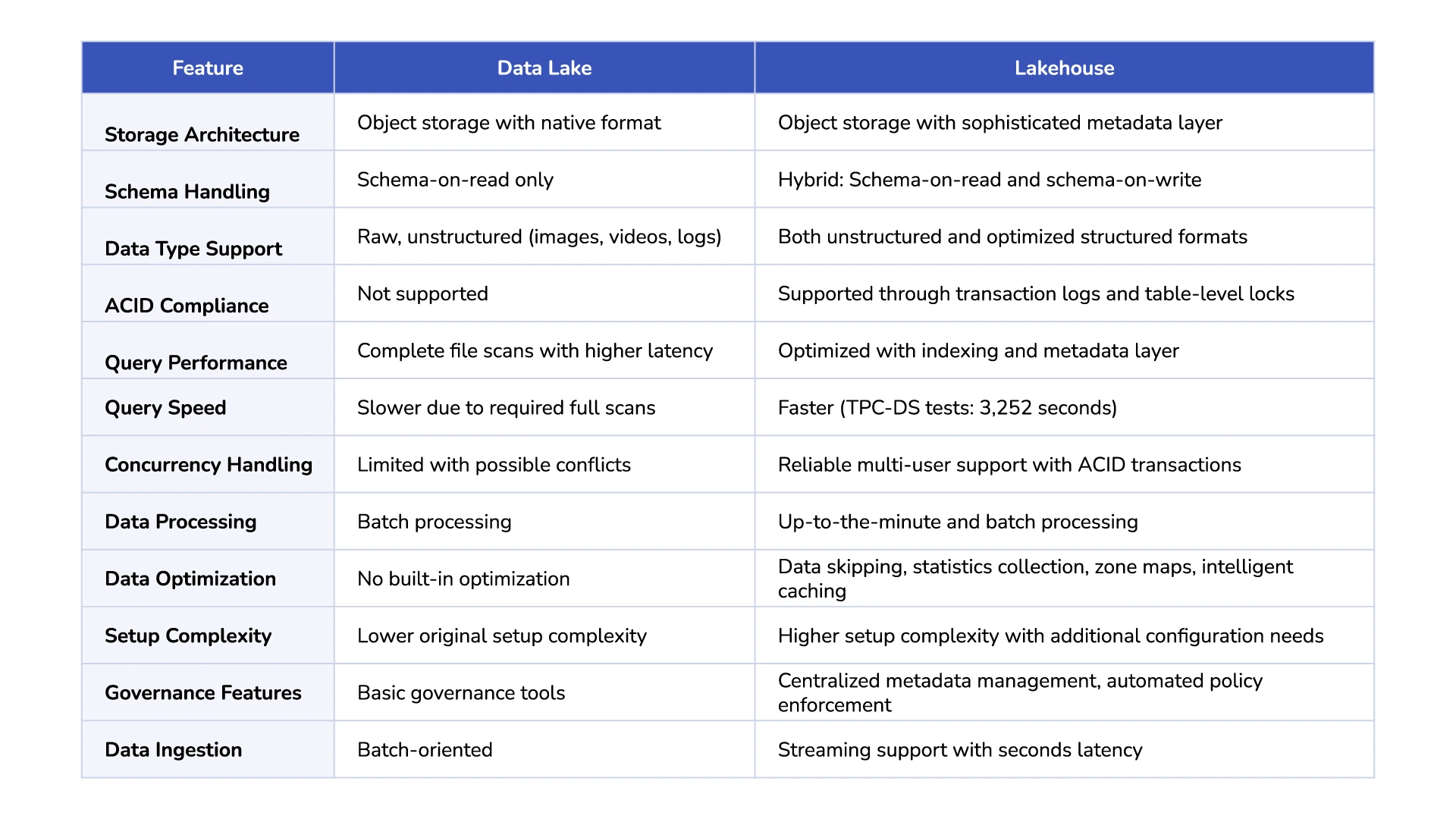
Data lakes use a flat architecture with object storage that keeps information in its native format. This flat structure gives maximum flexibility but doesn’t optimize query performance well. Lakehouses keep the affordable object storage base and add a smart metadata layer to access and manage data faster. The lakehouse’s metadata structure comes in two forms – tabular (like Delta Lake and Hudi) or hierarchical (like Iceberg). This structure organizes data objects without changing their physical arrangement.
Schema Handling: Schema-on-Read vs Schema-on-Write
These systems have a main difference in when they apply structure to data. Data lakes use schema-on-read, which means they structure data only when it’s analyzed. This makes data ingestion quick but moves processing work to query time. Lakehouses mix both approaches. They combine schema-on-read flexibility with schema-on-write features to structure data during writing. This mixed approach gives flexibility for unstructured data and better analytics performance.
Data Types Supported: Raw vs Structured and Semi-Structured
Both systems work with different data types, but they handle them differently. Data lakes are great at storing unstructured data like images, videos, and logs next to structured datasets. Lakehouses keep this flexibility and add better storage formats and metadata management to improve query speed for all data types. On top of that, they support structured table formats that process both raw and refined data efficiently on one platform.
ACID Compliance: Absent in Lakes, Present in Lakehouses
The biggest change in lakehouses is ACID transaction support. Regular data lakes don’t have ACID guarantees, which creates problems with reliability when multiple operations happen at once. Lakehouses fix this through transaction logs (Delta Lake), table-level locks (Hudi and Iceberg), or atomic operations. These features ensure atomicity, consistency, isolation, and durability. Users can now access data reliably at the same time, preventing corruption and getting the same transaction safety that traditional database systems offer.
Performance Metrics That Matter

Performance metrics play a crucial role in determining if data systems work well for big data teams. The comparison between data lakes and lakehouses shows big differences in how they operate based on several key metrics.
Query Speed: Raw File Scans vs Indexed Tables
Data lakes run full file scans to query data, which creates higher latency for complex analyzes. Lakehouses use optimized metadata layers with indexing capabilities that substantially reduce query execution time. Delta Engine demonstrations have shown query performance that matches or exceeds leading cloud data warehouses at a lower price point. Some measurements show the Delta Engine completed TPC-DS tests in 3,252 seconds while traditional data warehouses took up to 37,283 seconds.
Concurrency Handling: Multi-user Access and Isolation
Traditional data lakes face challenges with concurrent access because they lack reliable mechanisms to prevent conflicts when multiple users modify data at the same time. This creates potential data inconsistencies. Lakehouses fix this problem through ACID transactions that provide isolation levels to maintain data integrity during concurrent operations. The result is a reliable multi-user environment where analysts, data scientists, and automated processes can work together without risking data corruption.
Streaming Support: Batch-Only vs Real-Time Ingestion
Data lakes typically process information in batches, which creates a delay between data arrival and analysis availability. Lakehouses expand their capabilities by supporting real-time ingestion through streaming engines integration. Systems like Delta Lake make “streaming data lakehouse architecture” possible with just seconds of latency. This makes them ideal for time-sensitive applications like fraud detection and operational monitoring.
Data Skipping and Caching: Absent vs Built-in Optimization
Traditional data lakes lack data skipping, a technique that bypasses irrelevant data during queries. Lakehouses take a different approach by implementing automatic statistics collection, zone maps, and intelligent caching to optimize performance. These features can cut down the amount of scanned data by orders of magnitude. This dramatically improves query response times for analytical workloads.
Real-World Use Cases and Industry Adoption
Companies of all types are building data lake and lakehouse architectures to solve their business challenges. These ground applications demonstrate how each approach adds value based on specific use cases.
Retail: Inventory Optimization and Customer Behavior
Retail companies utilize data lakehouses to prevent stockouts by monitoring inventory immediately. They analyze customer purchase patterns, priorities, and online interactions to create customized marketing campaigns and product suggestions. This combined approach helps retailers segment customers based on their buying history and demographics that leads to better participation and sales.
Healthcare: Patient Monitoring and Predictive Analytics
Healthcare organizations’ data lakehouses combine patient records with immediate sensor data from wearable devices to detect health risks early. Mayo Clinic employs a lakehouse that brings together structured patient records with unstructured IoT device data for customized care. Healthcare systems can optimize operations, enhance patient outcomes, and welcome new innovations.
Finance: Fraud Detection and Risk Modeling
Banks and financial firms use lakehouses to spot fraudulent transactions by analyzing patterns in massive datasets. JP Morgan Chase analyzes structured transaction data with unstructured social media sentiment to detect fraud better. These systems handle 50,000+ events per second during peak traffic and spot anomalies in under 500ms.
IoT and Sensor Data: Real-Time Processing at Scale
Modern electric vehicles create over 400KB of data every minute, generating 1,000-3,000 data points per car. The lakehouse architecture helps process this sensor data immediately that powers applications like battery health monitoring and autonomous driving systems.
Implementation Complexity and Cost Considerations
Building data infrastructure requires key decisions about complexity, tooling, costs, and governance that shape operational success.
Setup and Maintenance: Manual Coding vs Managed Platforms
The original data lake deployment needs less technical expertise than a lakehouse architecture setup. Data lakes are simpler but lack governance tools. Lakehouses need extra configuration to enable their advanced features. Companies choose between self-managed systems that need teams with specialized knowledge, fully-managed platforms with higher hardware costs but lower operational work, or serverless options with minimal maintenance needs.
Reduced Time-to-Insight Across Departments
Salesforce to sap system integration shrinks the gap between collecting data and taking action. AI analytics platforms remove old bottlenecks by constantly taking in data and showing insights as patterns emerge. This speed boost is remarkable – reports that took four hours now take just 30 minutes, cutting time by 80%.
Modern business structures adapt to meet these faster needs. Companies create smooth data movement within their sap and salesforce integration through integrated data hubs. This makes quality data ready to analyze faster. Smart data catalogs help teams share and understand information better.
Tooling Ecosystem: Spark, Trino, Presto, and More
The lakehouse ecosystem has grown significantly and now supports many analytics engines:
- Apache Spark handles general-purpose processing tasks
- Trino and Presto enable interactive SQL querying
- ClickHouse and StarRocks provide immediate OLAP capabilities
These tools exploit open table formats such as Apache Iceberg, Delta Lake, and Apache Hudi to enable transactional data management.
Cost Efficiency: Storage vs Compute Trade-offs
Traditional data warehouses bind storage and compute together. Scaling either component means scaling both. Data lakes and lakehouses separate these resources, which allows independent scaling based on actual needs. The “DuckLake” approach shows this efficiency by enabling serverless, consumption-based queries without idle compute costs.
Governance and Compliance: Metadata and Access Control
Data lakehouses excel at governance through centralized metadata management, automated policy enforcement, and unified access controls. These features ensure data quality when ingesting while staying flexible for schema changes.
Comparison Table
Conclusion
Roles: Use a data lake for low-cost raw/archival storage and large-scale ingestion; use a lakehouse when you need reliable, governed, fast analytics for streaming + BI + ML in one platform.
Performance & concurrency: Lakehouses handle many concurrent users and mixed workloads better (fewer retries, faster queries, less pipeline fragility).
Governance & reliability: ACID tables and schema evolution (e.g., Delta/Iceberg/Hudi) reduce drift, simplify lineage, and improve auditability.
Cost & TCO: Keep cheap storage in the lake; move only curated, frequently queried data to the lakehouse. Expect lower operational overhead from less reprocessing and simpler access control.
Data products: Organize by tiers (raw → curated → serving) so teams can ship self-serve datasets with clear SLAs and ownership.
SAP alignment: Bridge your SAP BTP/Datasphere/HANA data with open table formats to avoid lock-in while keeping SAP as the system of record.
When to choose what:
- Prefer a lakehouse for governed analytics, evolving schemas, and cross-functional consumption.
- Prefer a lake for inexpensive landing/retention, rarely queried data, or exploratory data science at low cost.
- Pragmatic path: Pilot 1–2 high-value use cases first; keep raw in the lake, materialize curated/serving layers in the lakehouse, iterate; don’t big-bang migrate.
- KPIs to track: Query latency & success rate, cost per query/hour, data freshness SLA, failed job rate, active users/data product adoption.
- Common pitfalls: Unbounded compute on ad-hoc queries, mixing table formats without a policy, weak governance/lineage, and skipping enablement for analysts.
Choose the blend that fits your workloads, governance needs, and team maturity today—with a clear path to scale tomorrow.
Explore your data options with Tachyon
Talk to our experts about how to modernize your data architecture with SAP and cloud-native solutions.